Jenkins -- Controller
Jenkins is one of the most sophisticated Java code bases I have ever read so far. I feel it is harder to read even than the Spring codebase. It is a combination of DSL parser, annotation processing, remote JVM, sandboxing, web design and etc. You can learn a lot of skills from this project. Also, the huge amount of must-have plugins are also intimidating for beginners. I hope this post can shed some light on the Jenkins internals.
By the way, I found its official plugin tutorial is super helpful to grasp some basic idea about Action and jelly. Try it out if you haven’t!
First, we should know how Jenkins runs and what components it has. Jenkins has two roles: controller and worker. Controller is responsible for managing all definitions and states. Worker is responsible for executing jobs. Most complicated things happen inside the controller. The root entry for the controller code is Jenkins.java. The controller maintains a list of jobs. A job can be executed. Each single execution is called a Run/Build. All these entities are dumped to disk as ${JENKINS_HOME}/jobs/<job-name>/builds/<build-id>. For example, this build.xml is a sample run of a Jenkins pipeline.
Job
Job.java is an abstract class. There are many concrete job types. The jenkins-core package only defines one call Freestype project. The workflow-job-plugin package defines another very popular one WorkflowJob.java , aka, Pipeline. All these concrete types of jobs are registered in the Extension List Store. You can get all registered job types by running below script in the Jenkins Script Console.
1
2
3
4
5
6
7
8
9
10
11
12
import hudson.model.TopLevelItemDescriptor
TopLevelItemDescriptor.all().each { descriptor -> println descriptor.displayName }
=>
Freestyle project
Maven project
Pipeline
External Job
Folder
Multi-configuration project
Multibranch Pipeline
Organization Folder
So how does this work? In python, we can achieve subclass registration easily using the __init_subclass__ hook. Java is different. First, Java does not provide this hook. To achieve this goal, developers usually turn to annotations. Specific to Jenkins, it is @Extension. Jenkins core provides an extension finder called sezpos, and hooks it up in the Jenkins bootstrap process, so it builds the extension store early. Second, in python we need to explicitly import the subclasses to make them registered otherwise the runtime does not know their existence. This is not a problem in Java. Java is a static language. In the compilation stage, SezPoz’s annotation processor scans for annotated classes or methods and generates indexing files under META-INF/annotations. At runtime, SezPoz’s API loads these indexes via Index.load(…) to discover implementations (or even specific methods or static fields) with metadata attached — all lazily loaded when needed. What about subclasses defined in third party libraries? It is the same. SezPos scans each package’s META-INF/annotations folder. Therefore, in some sense, subclass registration is better supported in Java!
One more note about ExtensionFinder. Most of its member methods are generic. It can not only deal with @Extension annotation but also some other SezPos based annotations such as OptionalExtension. I see @OptionalExtension is used more often than @Extension because it can defines the requirements such that the subclass is only registered when a dependent package exists.
When you add a new job using Jenkins UI. It pops up a list with all existing job types. With a fresh installation, I only see Freestype project and Pipeline. 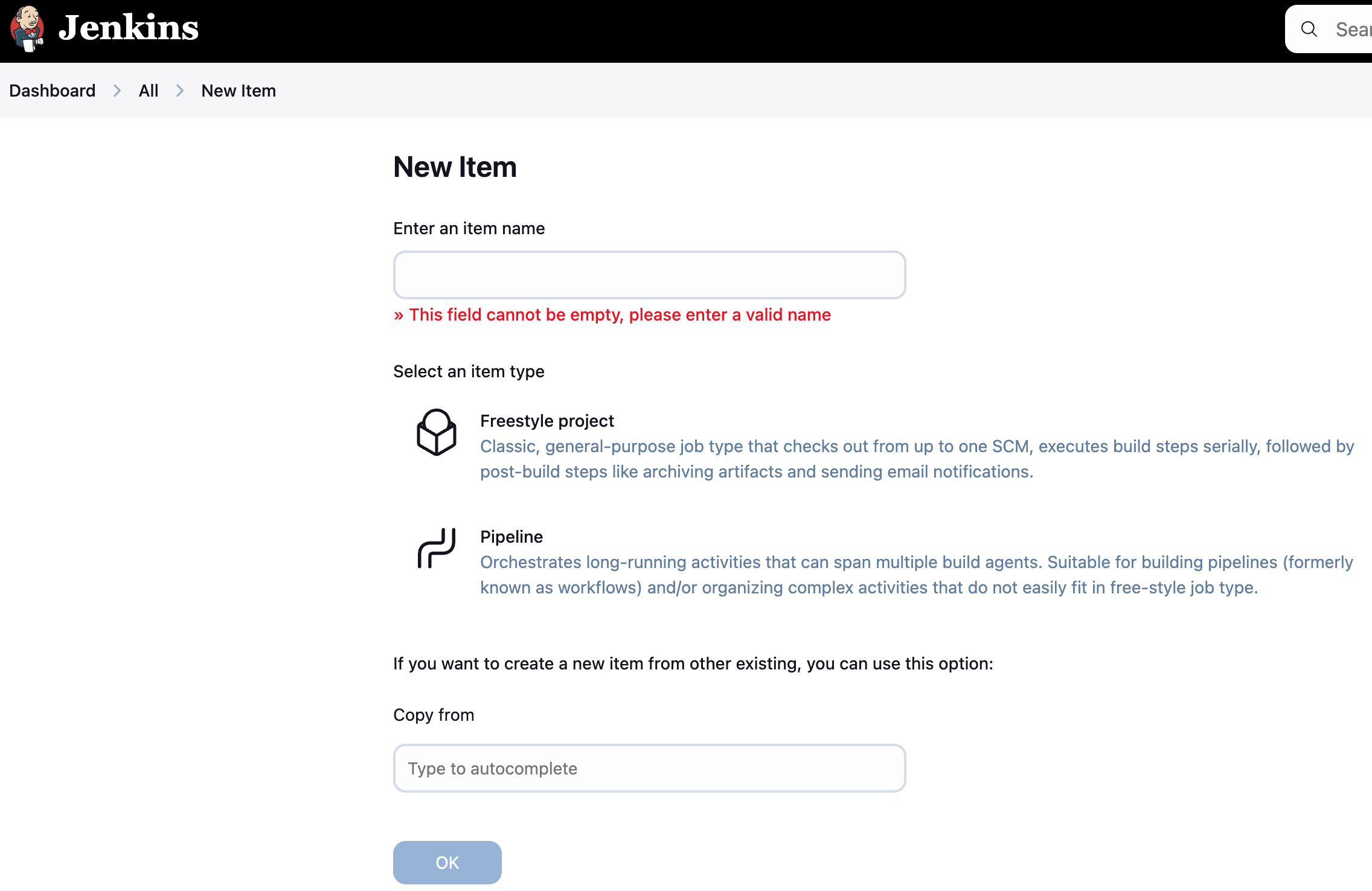 . The next section walks you through Pipeline gotchas.
. The next section walks you through Pipeline gotchas.
WorkflowJob, aka Pipeline
Pipeline needs 3 packages to run: workflow-job-plugin, workflow-cps-plugin and pipeline-model-definition-plugin. See the bottom table for their relationship. There are two types of pipelines: declarative and scripted.
Declarative is like
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
pipeline {
agent any
stages {
stage('Build') {
steps {
echo 'Building...'
}
}
stage('Test') {
steps {
echo 'Testing...'
}
}
}
}
Scripted is like
1
2
3
4
5
6
7
8
9
node {
stage('Build') {
echo 'Building...'
}
stage('Test') {
echo 'Testing...'
}
}
To be honest, I do not see too many differences between the two styles, and more importantly, the declarative style is parsed as AST and then transformed to valid Groovy code as well. So eventually, the final representation is Groovy.
Parsing, Validation and Transformation
The declarative style cannot run directly. Checkout the dev guide for how this part works. We will use the example build result build.xml to illustrate the parsing process. Most parsing logic happens in ModelParser.groovy. At the top level, you should define agent and stages. In our example, the agent is defined as
1
2
3
4
5
6
agent {
kubernetes {
defaultContainer "manage-kafka";
yaml "..."
}
}
I suggest you spend 5min reading the parseAgent function implementation. It is amazing to see that agent {...} is parsed as a function call and kubernetes {...} is parsed as a function call as well. Recall that in Groovy, functions can be called either in the form of func(arg1, arg2) or func arg1 arg2 and the last argument can be a closure, so agent {...} means calling a function named agent with only one argument and this argument is a closure. Amazing right? Groovy is born for DSL. The last time I had the similar excitement was when I realized Ruby is born for DSL.
A natural follow-up question is where function kubernetes is defined.
EnvVar
Extension Annotation
- How Symbol annotation work
Script Console
Agent
Pipeline execution
- It is a groovy script
- so how the functions are called? where defined? what arguments?
1
2
import org.jenkinsci.plugins.pipeline.modeldefinition.agent.DeclarativeAgentDescriptor
DeclarativeAgentDescriptor.all().each { descriptor -> println descriptor.name }
The result is
1
2
3
4
5
6
7
docker
dockerfile
kubernetes
dockerContainer
label
any
none
Step descriptor
1
2
3
4
import org.jenkinsci.plugins.workflow.steps.StepDescriptor
def stepNames = StepDescriptor.all().collect { it.functionName }.sort()
stepNames.each { println it }
println "\nTotal steps: ${stepNames.size()}"
The result list is long, so I omit them. You could found sh, sleep etc show up in the list.
WebApp
| Annotation | Purpose | Resulting Endpoint |
|---|---|---|
@Exported | Included in /api/json output | /.../api/json?tree=fieldName |
doXYZ() | Bound to URL endpoint | /.../xyz |
getXYZ() | Usually bound as a property | /.../xyz/ (sometimes), or api/json field |
UI
- How the UI is hooked up? Ex. the pipeline image.
{kind=link}
Plugin/Package Index
| Package | Depends On | Purpose | Notes |
| jenkins-core | Define core concepts such as Job, Run, Action, Extension, etc. | ||
| jenkins-war | Start the Jenkins controller and web app, so user can interact with the UI. It uses Stapler web framework, which exports data as a URL (e.g., getting job info as JSON or XML via an endpoint like /job/my-job/api/json). | This package exist in the same repo as jenkins-core. | |
| workflow-job-plugin | workflow-api-plugin | Provides the base job type (WorkflowJob, WorkflowRun) for pipeline jobs. | |
| workflow-cps-plugin | workflow-job-plugin | Provides the engine that runs Groovy-based scripted and declarative Pipelines. | |
| pipeline-model-definition-plugin | workflow-cps-plugin |
|